
얼레벌레
cs231n lecture 11 Detection and Segmentation 본문
Image Segmentation
- 픽셀 기반의 이미지 분석
- 이미지 분석의 목적: 각각의 픽셀들을 특정 class로 분류하고자 함

https://github.com/divamgupta/image-segmentation-keras
GitHub - divamgupta/image-segmentation-keras: Implementation of Segnet, FCN, UNet , PSPNet and other models in Keras.
Implementation of Segnet, FCN, UNet , PSPNet and other models in Keras. - GitHub - divamgupta/image-segmentation-keras: Implementation of Segnet, FCN, UNet , PSPNet and other models in Keras.
github.com
1. Semantic Segmentation
Classification과 마찬가지로 카테고리가 존재함.
But, image단위로 labeling을 하는 것이 아니라, 이미지 내의 모든 픽셀에 대해 독립적으로 labeling이 이루어짐
한계점: 픽셀을 카테고리로 labeling하는 것이기에, 하나의 이미지에 동일한 물체가 존재해도 단지 특정 카테고리 하나로 labeling된 픽셀 덩어리만 도출 가능
⇨ 이를 Instance Segmentation으로 극복
💡 Idea
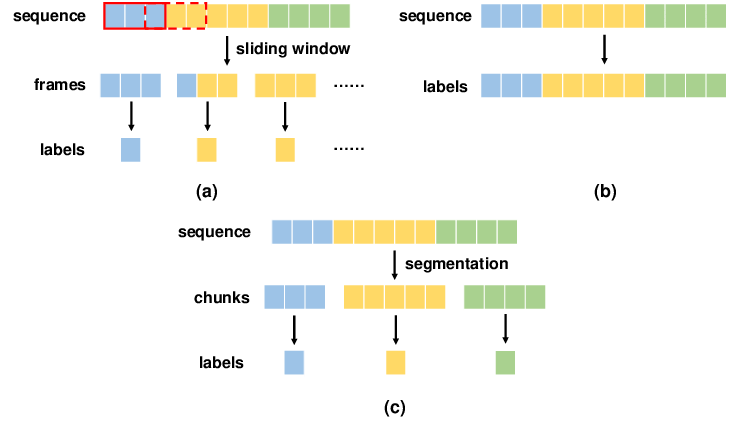
1-1. Sliding Window
고정 사이즈의 window가 이동하며, window 내에 있는 데이터를 이용해 문제를 풀이하는 알고리즘
모든 픽셀에 대해 작은 영역으로 쪼개고(window 생성) 모든 영역에 대해 forward/backward pass를 진행
Semantic Segmentation에 적용하기엔 비용이 큼 + 인접한 다른 영역끼리 공유하는 공통적인 특성이 있을 수도 있는데 하나의 카테고리로 분류해버림
1-2. Fully Convolutional Network

여러층의 convolutional layer에서 특정한 사이즈를 유지해 최종적으로 하나의 텐서를 도출하고, 모든 픽셀에 대해 카테고리를 분류
⇨ original image의 size를 유지하며 모든 픽셀을 분류하다보니 계산량 문제
⚛︎ feature map을 downsampling하고 다시 upsampling하는 방식을 사용
Upsampling ?
- convolution을 거치며 줄어든 feature map의 크기를 다시 기존 input 사이즈로 늘려 빈공간을 채우는 과정
1-2.1 Unpooling

1-2.2 Max Unpooling

1-2.3 Transpose Convolution

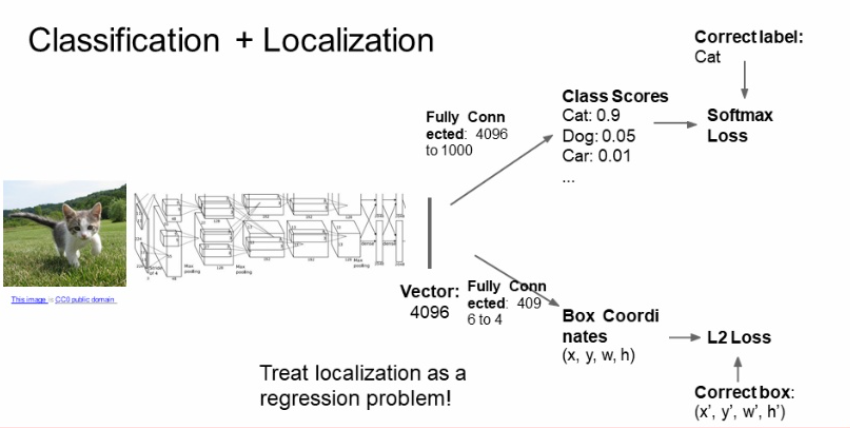
2. Classification + Localization
물체 분류 + 특정 물체의 위치 정보를 알고자 할 때 사용
object detection과는 다름 ⇨ 다양한 물체 분류 + 다양한 물체에 대한 위치 정보를 제공
CNN과 유사한 구조를 지녔으나 끝쪽에 box coordination을 하는 FC layer가 추가됨
1️⃣ object의 bounding box를 찾는 작업 + 2️⃣ Bbox내의 object의 카테고리를 분류하는 작업, 즉 multitask이므로 loss를 2개 사용
1️⃣의 경우는 GT Bbox와 예측된 Bbox 간의 loss를 L2 loss(or L1, smooth L1)로 디자인
2️⃣의 경우 Class Score의 loss를 Softmax loss로 디자인
이러한 개념은 Human Pose Estimation에도 사용
- input은 사람 이미지, output은 관절에 대한 coordinates
- 예측된 관절에 대한 좌표에 대하여 regression loss(L1, smooth L1, L2 .. etc)를 계산하고 backprop으로 학습

3. Object Detection
카테고리는 고정된 채로, 입력 이미지에 따라 예측해야 하는 Bbox 수가 달라짐
Object Detection as Regression -? no !
Object Detection as Classification
3-1. sliding window algorithm
영역을 쪼개서 특정 영역에 대해서만 CNN의 입력으로 넣고, CNN은 이에 대해 classification을 진행함
이 때 카테고리 외에, 배경 또한 추가 해야함 -> 특정 영역에 object가 없는 경우 네트워크가 배경으로 예측하여 아무것도 없다는 것을 판단할 수 있도록 함
하지만 이렇게 하기엔 object가 어디에 존재하고, 몇 개 있을지 .. 등등을 모르기에 영역마다 CNN을 통과시키는 것은 불가
=> 사용 안함,, ;;

3-2. Region Based Model
Region Proposal Network [ ≔Region of Interest (ROI) ]
brute force 식이 아닌, Selective Search를 통해 object가 있을만한 여러개의 blobby한-뭉쳐 있는 공간들의 후보을 만들어냄
노이즈는 심하지만 recall은 높기에 우선 객체가 있을법한 후보에 대해서만 CNN의 입력으로 넣으면 비용이 훨씬 저렴해짐
이 후보를 대상으로 CNN을 함 ⇨ R(egional)-CNN

3-2.1 R-CNN
1️⃣ image를 입력받고 Selective Search를 통해 여러개의 ROI를 추출한다.
2️⃣ 추출된 ROI들을 CNN의 입력으로 사용하기 위해 FC layer 등을 이용하여 동일한 크기로 변환시키고 각각의 ROI를 CNN에 통과시킨다.
** Convolution layer은 input size가 동일하지 않아도 되지만, FC layer은 input size가 고정이므로 마지막 Convolution layer의 output size를 동일하게 해야 한다. 따라서 Convolution layer의 input부터 동일한 고정된 size로 입력하는 것이다.
3️⃣ CNN을 통과한 출력값에 대하여 SVM을 이용하여 특성 벡터와 관련된 클래스를 예측한다.
** 당시엔 CNN fine-tuning을 위한 train data가 충분하지 않아 softmax가 오히려 성능이 낮아 해당 논문에서 softmax가 아닌 SVM을 사용한다.
4️⃣ 대체로 CNN은 물체가 Bbox의 중심부에 위치하지 않아도 클래스 분류가 원활하다. 따라서 localization error을 줄이기 위해 Bbox reg 과정을 통하여 물체가 중심부로 오도록 위치를 조정해준다.
☹︎☹︎☹︎
당연히 brute force보다는 빠르지만 모든 ROI에 대하여 CNN을 거치고 forward/backward pass를 거친다면 시간이 상당히 소요됨
⇨ Fast R-CNN의 도입

3-2.2 Fast R-CNN
* R-CNN은 여러개의(약 2000개・・・) CNN을 사용하는 반면 Fast R-CNN은 단 하나의 CNN만을 사용하기에 더 좋은 성능을 낸다.
1️⃣ image를 입력받고 Selective Search를 통해 Region Proposal의 Bbox 좌표를 구한다
2️⃣ image를 CNN에 투영(project)하여 feature map을 추출한다
3️⃣ 1️⃣에서 구한 Bbox의 좌표값을 feature map에 투영하여 crop ⇨ CNN의 feature을 ROI끼리 공유
4️⃣ 투영된 ROI에 대해 RoI Pooling(미분이 가능하여 학습이 가능한 방법)을 진행하여 고정된 일정한 크기의 feature vector를 추출
5️⃣ FC layer의 입력으로 넣음
- 하나는 softmax를 통과하여 object classification
- 하나는 Bbox regression을 통해 Bbox의 offset을 계산하여 위치 조정
☹︎☹︎☹︎
마찬가지로 R-CNN보다 개선되었지만, Test time에서 SS에 대부분의 시간이 소요된다는 점에서 여전히 병목 중 하나
⇨ Faster R-CNN의 도입
+ 참고했던 블로그(실제 이 논문 리딩을 하신분,,)에서 R-CNN과 Fast R-CNN의 차이점이 SS와 CNN의 순서가 바뀐 것이랬는데 이해가 가질 않는다. 둘 다 SS를 통해 ROI를 구하고 난 다음, R-CNN은 이 각각의 ROI를 CNN를 통과 시키는 것이고, Fast R-CNN은 SS로 ROI를 구한 후, 이미지를 CNN에 통과시켜 feature map을 구한 이후에 그 feature map에서 ROI들에 관한 coordinates를 crop하고 ROI Pooling을 거쳐 FC layer에 들어가는 것 아닌가?,, 순서가 바뀐 것이 대체 어느 지점인건지 잘 모르겠음 ☹︎

3-2.3 Faster R-CNN
Selective Search에 시간이 많이 소요된다는 것이 여태까지의 문제점이었다. 따라서 Faster R-CNN은 이를 개선한 모델일텐데 어떻게?
⇨ SS는 cpu에서 돌기에 느림. 따라서 ROI를 생성하는 network도 gpu에 넣기 위하여 이를 Convolution layer에서 생성하고자 하는 것이다.
즉 RPN에서 사용하는 CNN과 classification/Bbox를 위해 사용하는 CNN을 공유하고자 함.
Fater R-CNN = RPN + Fast R-CNN
1️⃣ image를 입력받고 입력 이미지 전체가 network에 들어가 feature map 생성
2️⃣ Conv feature map과 RoI Pooling 층 사이의 Region Proposal Network(RPN)에서 자체적으로 ROI 추출
** 이 때의 RoI는 feature map의 RoI가 아닌 original image에서의 RoI임
3️⃣ 나머지 동작은 Fast R-CNN과 동일
3-3. Single Shot Method - YOLO / SSD
Region Proposal을 활용하지 않는, 분류(Classification)와 좌표추정(Regression)을 한 번에 처리하는 one-stage 알고리즘
- forwarding 한 방에 이미지에 대한 모든 추론 과정을 수행하는 one-stage ⇨ 각 region에 대한 독립적인 처리가 필요하지 않아 매〰️우 빠름
- R-CNN 계열은 two-stage여서 single shot method보다 더 높은 정확도를 가지지만 성능 차이는 많이 없다고 한다.
* YOLO(You Only Look Once)
YOLO, Object Detection Network
You Only Look Once : Unified, Real-Time Object Detection Joseph Redmon - University of ...
blog.naver.com
* SSD(Single-Shot multibox Detector)
SSD: Single Shot MultiBox Detector
SSD: Single Shot MultiBox Detector Wei Liu1, Dragomir Anguelov2, Dumitru Erhan3, Chri...
blog.naver.com
4. Instance Segmentation
Semantic Segmentation + Object Detection

Mask R-CNN
논문 - arxiv.org/pdf/1703.06870.pdf
처음 입력 이미지가 CNN과 RPN을 거치고 feature map에서 RPN의 RoI만큼 project한다.
이 다음 각 Bbox마다 Segmentation mask를 예측하도록 한다.
'AI > DL' 카테고리의 다른 글
| 논문리뷰) Deep Residual Learning for Image Recognition (0) | 2023.08.03 |
|---|---|
| 논문리뷰) Batch Normalization (0) | 2023.07.27 |
| 논문리뷰) Neural Networks for Machine Learning (0) | 2023.07.19 |
| [논문리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.09.30 |
| cs231n lecture 10 Recurrent Neural Networks (0) | 2021.08.20 |


