
얼레벌레
cs231n lecture 10 Recurrent Neural Networks 본문
RNN?
순환 신경망(RNN; Recurrent Neural Network)이란 인공 신경망의 한 종류
- 내부의 순환 구조가 포함되어 있어 시간에 의존적이거나 순차적인 데이터 학습에 활용됨 (EX) 시계열 데이터
- 데이터가 순환하기 때문에 끊임없는 정보 갱신 가능
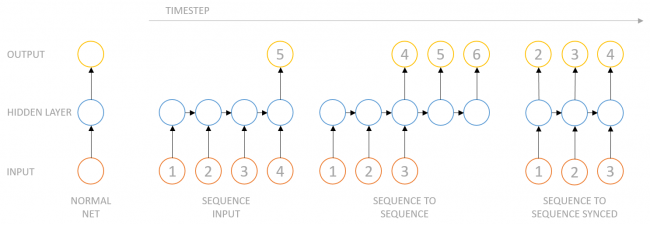
여태까지의 architectures(vanilla neural network) -> 단일 입력-단일 출력이었지만 모델의 유연화가 필요함
=> 다양한 입출력을 받아 가변 길이의 데이터를 다루도록 하는 paradigm : RNN
| one to many | 단일 입력-가변 출력 (ex) Image Captioning |
| many to one | 가변 입력-단일 출력 (ex) Sentiment Classification / Computer Vision Task |
| many to many (1) | 가변 입력-가변 출력 (ex) Machine Translation |
| many to many (2) | 가변 입력-가변 출력 (ex) Video Classification per each frame |
* machine translation
http://solarisailab.com/archives/2545
26. 텐서플로우(TensorFlow)를 이용해서 seq2seq 모델을 이용한 기계번역(Neural Machine Translation-NMT-) 구현
이번 시간에는 텐서플로우(TensorFlow)를 이용해서 seq2seq 모델을 이용한 기계번역(Neural Machine Translation-NMT-) 구현하는 법을 살펴보자. [1] seq2seq(Sequence-to-sequence) 모델 기계번역(NMT)를 구현하기 위한 se
solarisailab.com
* video classification
https://keras.io/examples/vision/video_classification/
Keras documentation: Video Classification with a CNN-RNN Architecture
Video Classification with a CNN-RNN Architecture Author: Sayak Paul Date created: 2021/05/28 Last modified: 2021/06/05 Description: Training a video classifier with transfer learning and a recurrent model on the UCF101 dataset. View in Colab • GitHub sou
keras.io

* RNN 동작 과정 ( Vanilla Neural Network )
1. input x to RNN
2. RNN이 지닌 hidden state가 new input에 따라 update
3. hidden state가 모델에 feedback -> input new x
- 출력값(y)를 가지려면 hidden state를 입력으로 하는 FC layer 추가해야 함

h0(initial hidden state)를 보통 0으로 초기화하고, f_w(h0,x1)으로 h1을 받음.
행렬곱의 합을 hidden state의 활성함수인 비선형 함수 tanh를 이용해 변환하여
이러한 연쇄적인 과정을 거쳐 가변 입력 xt를 받는다
2가지 입력(h, t)는 매번 달라지지만 가중치 행렬 W는 매번 동일함
왜 비선형함수 tanh를 사용하는가?
선형 함수인 ℎ(𝑥)=𝑐𝑥를 활성 함수로 사용한 3층 네트워크를 떠올려 보세요. 이를 식으로 나타내면 𝑦(𝑥)=ℎ(ℎ(ℎ(𝑥)))가 됩니다. 이 계산은 𝑦(𝑥)=𝑐∗𝑐∗𝑐∗𝑥처럼 세번의 곱셈을 수행하지만 실은 𝑦(𝑥)=𝑎𝑥와 똑같은 식입니다. 𝑎=𝑐3이라고만 하면 끝이죠. 즉 히든레이어가 없는 네트워크로 표현할 수 있습니다. 그래서 층을 쌓는 혜택을 얻고 싶다면 활성함수로는 반드시 비선형함수를 사용해야 합니다.

RNN 모델에 'hell'을 넣어 'o'를 출력하고자 한다.
가진 학습데이터의 글자는 'h','e','l','o'이고 이를 one-hot vector로 각각 변환한다.
x1 = [1,0,0,0]을 기반으로 하여 h1 = [0.3,-0.1,0.9]를 update하고, 또 이 hidden state를 기반으로 하여 y1을 구함. 정답에 해당하는 것은 진한 녹색인 'e'(2.2)이어야 하는데, 실제로는 'o'가 예측
어쨌든 이러한 과정으로 두번째, 세번째, 네번째 step도 hidden state를 update하게 되는데, 이것을 순전파(foward propagation)라고 함
기본구조를 이해하기 위한 character level model (hello로 다음 문자 예측)
첫번째 문자만 부여한 후 확률분포를 이용해 다음 문자 샘플링-> 다음 스텝의 네트워크 입력으로 넣어줌
이 과정을 반복하여 전체 문장을 생성하기 위해 매 스텝마다 확률분포에서 문자를 뽑아냄
여기서 가장 높은 스코어만 뽑아내지 않는 이유는 일반적으로 확률 분포에서 샘플링하면 모델에서의 다양성을 얻을 수 있음

* Many to Many의 경우
출력값 yt가 나와 매스텝의 class score이 됨 -> 각 스텝마다 개별적으로 yt에 대한 loss 계산(softmax loss)
최종 loss는 각 스텝의 loss의 합이 됨. Backprop고려 시 dL/dW로 각 스텝의 local gradient를 구하고, 각각을 더하면 최종 gradient

* Sequence to Sequence: Many-to-one(encoder) + One-to-many(decoder) => Machine Translation
- Many to one - 최종 hidden state가 전체 시퀀스의 내용에 대한 요약이기에, ht에 관해서만 출력값 y가 나옴
- One to many - 고정 입력은 initial hidden state(h0)을 초기화하는 용도로 사용하고, 모든 스텝에서 출력값이 나옴

Backpropagation through time (BPTT)
출력값들의 Loss를 계산해 final loss를 얻음
전체 시퀀스를 가지고 loss를 backp하기에 모델이 느릴 것임고 메모리 용량이 클 것임
⇨ 이런 계산량 문제를 해결하기 위해 Truncated Backpropagation through time 을 사용함
Truncated Backpropagation through time
전체 스텝을 여러개의 batch로 나눔
이전 batch에서 hidden state를 가져와서 foward pass를 진행하고 backprob은 현재 배치만 진행
** RNN 전체 구현 과정 참고
https://gist.github.com/karpathy/d4dee566867f8291f086
Minimal character-level language model with a Vanilla Recurrent Neural Network, in Python/numpy
Minimal character-level language model with a Vanilla Recurrent Neural Network, in Python/numpy - min-char-rnn.py
gist.github.com
1. Image Captioning - natural language model과 CNN을 동시에 backp하여 학습
Image Captioning? ⇨ 어떤 이미지를 설명하는 캡션을 자동으로 생성하는 것
이미지 인식과 더불어 NLP까지 필요로 하여 매우 어려움
입력 이미지를 받아 semantic한 feature들을 이미지에 encode하여, CNN을 통해 요약된 이미지정보 vector를 생성한다.(softmax score을 사용x)
이후 이 vector를 RNN의 입력초기값으로 넣고 text sequence로 input feature을 decode한다.
+ 이 때 이전과 다르게 이미지정보도 넣어줘야 하므로 세번째 가중치 행렬을 추가해야 함
+ train시킬 때 모든 caption의 종료 때 토큰을 삽입하여 토큰이 나오면 시퀀스가 끝난다는 것을 알려줘야 함
r로 구현하기 https://blogs.rstudio.com/ai/posts/2018-09-17-eager-captioning/
RStudio AI Blog: Attention-based Image Captioning with Keras
Image captioning is a challenging task at intersection of vision and language. Here, we demonstrate using Keras and eager execution to incorporate an attention mechanism that allows the network to concentrate on image features relevant to the current state
blogs.rstudio.com
1-1 Image Captioning with Attention
모델이 이미지에서 보고싶은 위치에 대한 분포까지 나타냄
soft attention / hard attention
관련문헌

2. VQA(Visual Question Answering)
VQA? ⇨ 이미지(Visual)과 그 이미지에 대한 질문(Question)이 주어졌을 때, 해당 질문에 부합하는 답변(Answer)을 만드는 것
CNN에서 받은 이미지 요약 정보와 질문 벡터를 RNN에 input(즉, 입력 벡터가 2개) -> 이 벡터들을 조합하여 질문에 대한 분포를 예측함

* Multilayer RNN
hidden state층을 2개~ 4개까지 사용하여 깊은 모델 생성
⇨ 더 복잡한 특성을 학습할 수 있게 됨.
⇨ BUT! exploding/vanishing gradient 문제 발생 가능

이전 hidden state와 입력값을 stack하여 backpropagation을 행하며 tanh gate를 거치고, mul gate를 통과한다.
모든 rnn cell에서 가중치 행렬의 일부를 곱하게 됨
⇨ 비효율적 ☹︎
Largest singular value > 1:
Exploding gradient
↑ gradient clipping
Largest singular value < 1:
Vanishing gradient
↑ LSTM
Backprop 시 발생할 수 있는 문제점
- Exploding gradient
gradient 값이 너무 커져 한 번에 큰 update로 잘못된 결과가 나오는 문제
⇨ gradient clipping으로 해결 가능
* gradient clipping : 상수값의 threshold를 지정해 gradient가 이보다 크면 값을 감소시켜 갱신하는 방식

- Vanishing gradient

backprop 과정에서 chain rule을 이용해 최종 미분 값을 구한다. 두 hidden state간의 미분값을 구하면 W_h를 구하는데, 모든 timestep에서 동일한 W_h를 사용하기에 미분값이 동일하게 된다. 이 때, W_h의 크기가 너무 작아지는 경우 작은 값끼리 곱하면 더더욱 작은 값의 결과가 나오고 최종적인 gradient가 매우 작아진다.
이렇게 과거의 내용을 기억하지 못하게 되는 문제점을 별도의 메모리를 이용해 해결한 것이 LSTM
LSTM (Long Short Term Memory)


https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
Long Short-Term Memory (LSTM) 이해하기
이 글은 Christopher Olah가 2015년 8월에 쓴 글을 우리 말로 번역한 것이다. Recurrent neural network의 개념을 쉽게 설명했고, 그 중 획기적인 모델인 LSTM을 이론적으로 이해할 수 있도록 좋은 그림과 함께
dgkim5360.tistory.com
+ GRU(Gated Recurrent Unit)
cell state를 사용하지 않고 hidden state에서 정보를 계속 유지해 나간다.
효과적인 RNN 학습 · ratsgo's blog
이번 글에서는 Recurrent Neural Network(RNN)을 효과적으로 학습시키는 전략들에 대해 살펴보도록 하겠습니다. 이 글은 Oxford Deep NLP 2017 course을 기본으로 하되 저희 연구실 장명준 석사과정이 만든 자료
ratsgo.github.io
'AI > DL' 카테고리의 다른 글
| 논문리뷰) Deep Residual Learning for Image Recognition (0) | 2023.08.03 |
|---|---|
| 논문리뷰) Batch Normalization (0) | 2023.07.27 |
| 논문리뷰) Neural Networks for Machine Learning (0) | 2023.07.19 |
| [논문리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.09.30 |
| cs231n lecture 11 Detection and Segmentation (0) | 2021.08.20 |


