
얼레벌레
논문리뷰) GRU(Gated Recurrent Neural Network) 본문
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Abstract
LSTM과 GRU 등의 gating mechanism을 적용한 정교한 유닛으로 polyphonic music model과 speech signal model을 검증하고 기존의 vanilla RNN과의 비교를 진행한다.
1. Introduction
최근 RNN이 기계 번역과 같은 작업에서 좋은 성능을 보이는데 Vanilla RNN이 아닌 LSTM/GRU를 유닛으로 사용함으로써 이전엔 불가능했던 성과를 이루고 있다. 본 논문에서는 두 유닛들을 비교하고 tanh를 사용한 유닛과의 비교도 진행한다. 실험에 의하면 고정된 개수의 파라미터를 사용한 GRU에서 CPU time의 convergence나 파라미터 update generalization 관점에서 LSTM보다 더 좋은 성능을 보이는 것도 발견했다.
2. Background: Recurrent Neural Network


RNN은 연속적인 hidden layer로 구성되었으며 activation이 previous time에 지속적으로 의존하는 neural network로 다양한 길이의 sequence input을 다룰 수 있다. 하지만 gradient vanishing/exploding으로 인해 gradient 규모의 변화나 장기 의존성의 영향이 단기 의존성의 영향보다 숨겨져 있게 되어 장기 의존성을 포착하는 RNN을 훈련시키는 것에 어려움이 생긴다.
이에 대한 두가지 접근방법으로
1. 더 나은 학습 알고리즘을 고안한다. ex) clipped gradient 사용, second-order method 사용(second derivative가 first derivative와 동일한 성장패턴을 가지는 경우 문제에 덜 민감하게 된다)
2. 더 정교한 activation function을 고안한다 - LSTM/GRU
3. Gated Recurrent Neural Networks
3.1 Long Short-Term Memory Unit
3.2 Gated Recurrent Unit
3.3 Discussion
LSTM과 GRU의 공통점과 차이점을 제시한다.
- 공통점
- t와 (t+1) 사이에 update에 관련한 추가적인 component의 존재
기존 RNN은 activation이나 unit의 내용을 현재 인풋과 이전의 hidden state로 계산한 새로운 value를 대체했다면, 이 component로 LSTM/GRU는 존재하는 내용을 유지하면서 새로운 내용을 계속 얹을 수 있게 되었다.
- 차이점
- LSTM에만 존재하는 특징으로
- input gate/ reset gate의 위치
4. Experiments Setting
4.1 Tasks and Datasets
sequence modeling 수행에서 LSTM, GRU, tanh 유닛을 비교한다. sequence modeling은 주어진 훈련 시퀀스에서 log-likelihood를 최대화하며 sequence별로 확률분포를 학습시키는 것을 목적으로 한다.

Polyphonic music modeling - 4가지 music datasets 사용 / output unit으로 logistic sigmoid 함수
speech signal modeling - Ubisoft의 2가지 데이터셋을 사용 / output layer로 20개의 구성요소를 가진 가우시안 사용
4.2 Models
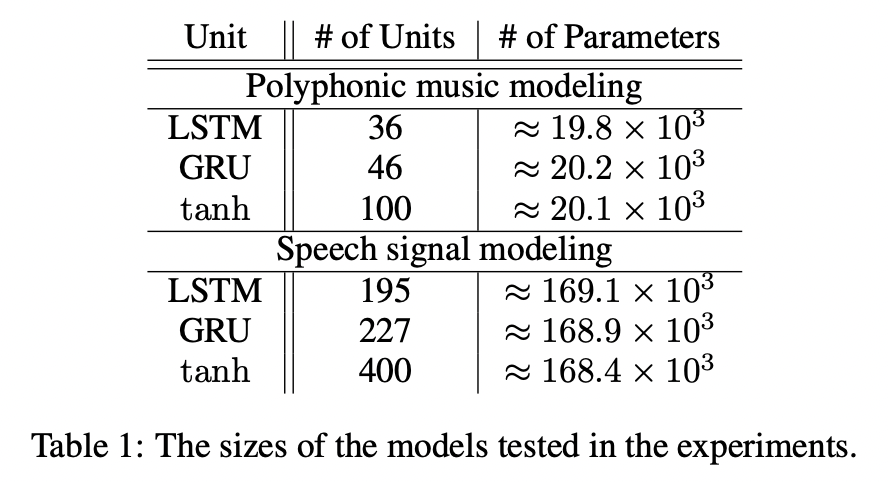
세가지 유닛간 공정한 비교를 위해 거의 똑같은 개수의 파라미터를 가지게 하였다. 또한 의도적으로 overfitting을 막기 위해 모델을 충분히 작게 만들어 비교가 용이하게 한다. 각 모델을 RMSProp으로 훈련시키고 0.075로 고정된 표준편차를 가진 weight noise를 사용하며, 각 업데이트마다 1보다 큰 경우 exploding gradient를 막기 위해 기울기의 norm을 1로 지속적으로 조정시킨다. unifrom distribution (-12, -6)에서 샘플링된 10개의 log-uniform candidates 사이에서 검증 성능을 최대화하기 위한 learning rate를 선택한다.
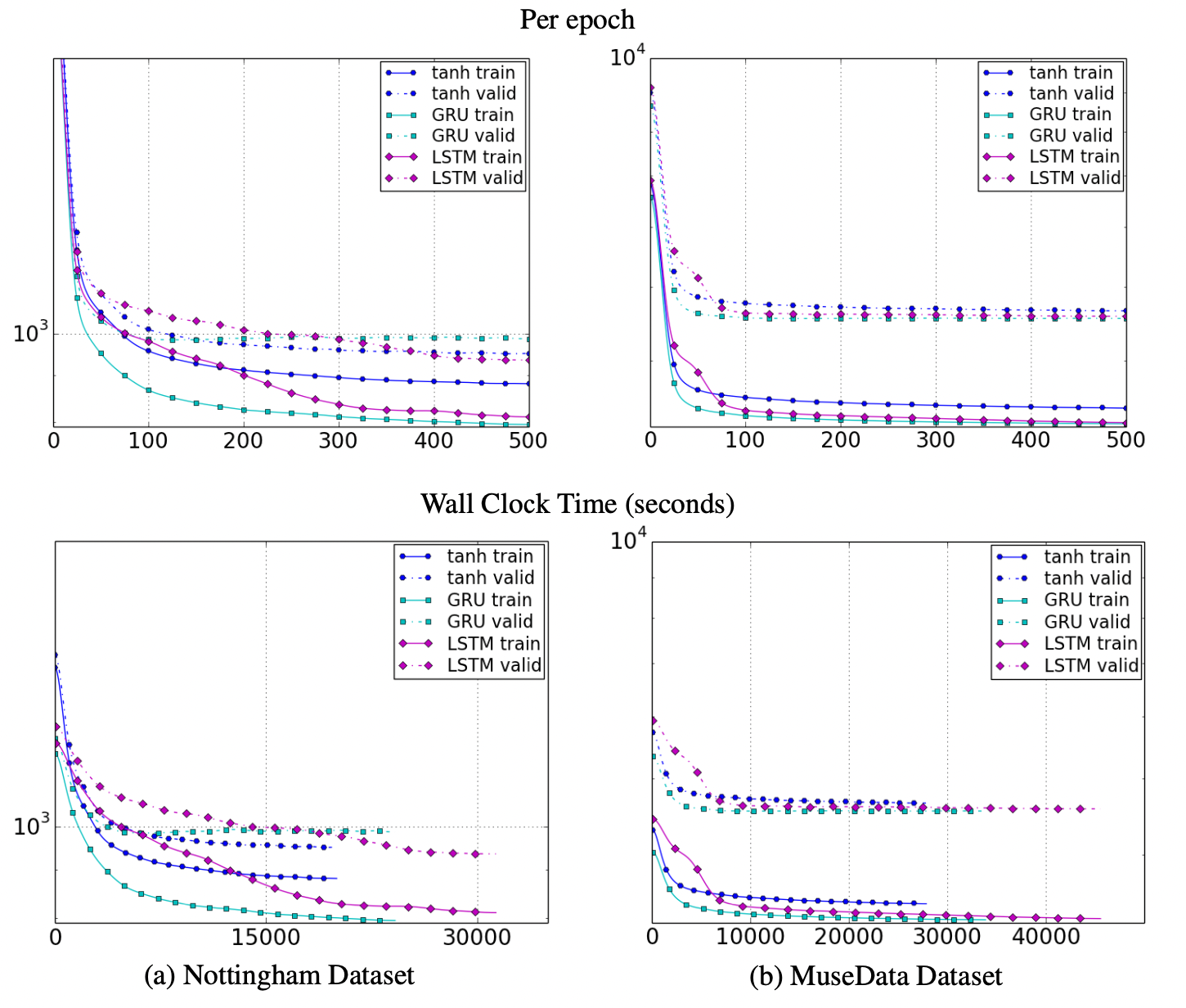
5. Results and Analysis

6. Conclusion
본 논문에서는 LSTM, GRU 그리고 기존의 tanh units로 평가를 진행하며 기존의 방법보다 gated mechanism이 더 좋은 성능을 보였지만 LSTM과 GRU 사이에는 우위를 가리지 못하여 향후 연구에서 더 철저한 실험이 진행되어야 한다.
'AI > DL' 카테고리의 다른 글
| 논문리뷰) Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory (0) | 2024.01.16 |
|---|---|
| 논문리뷰) Deep Residual Learning for Image Recognition (0) | 2023.08.03 |
| 논문리뷰) Batch Normalization (0) | 2023.07.27 |
| 논문리뷰) Neural Networks for Machine Learning (0) | 2023.07.19 |
| [논문리뷰] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.09.30 |



